Restaurant Suggestor
I have created this project to help users find restaurants based on their favirote dishes and area in which they what to search the restaurants to dine-in.
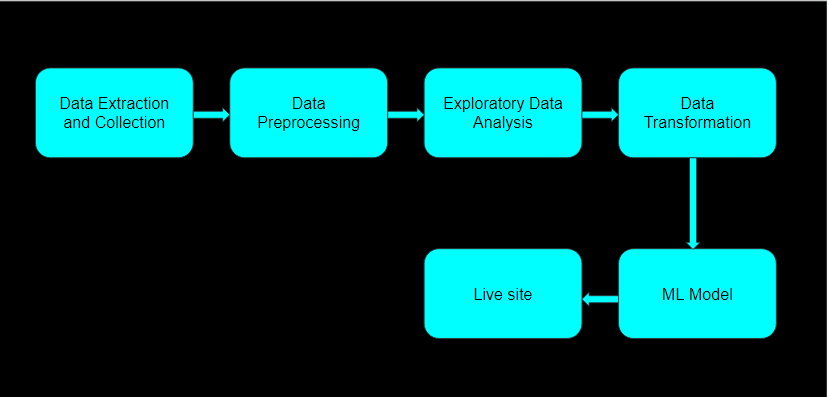
This Project is sectioned into following sections.
- Data Extraction and Collection
- Data Preprocessing
- Exploratory Data Analysis
- Data Tansformation
- Building Machine learning models
- Developing a working model site
⇛ Data Extraction and Collection
To beign with I collected Zomato Restaurants Data from
kaggle.com and Extracted other data from
Swiggy. Zomato and Swiggy are popular apps where most of the food orders are placed on daily Basis
by people in Bengaluru.
The Project involes restaurants in Bengaluru.The Dataset is
obtained by scraping the two popular
online delivery systems. Swiggy and Zomato. The dataset is separately obtained and later combined to
make it as one file. The size of the individual files are 0.5GB and 100MB respectively from Zomato
and Swiggy.
The main Aim of this project is to prepare a model which
recommends restaurants based on dish or
restaurant type. The final output is to build a web app which shows the user his nearest best
afforable, high quality restaurants with directions to reach to the place when a particular
restarant is selected.
**** Please click on Data Preprocessing tab to view the data extraction code or click here
⇛ Data Preprocessing
The Data came in two separate files. The exctracted data from
Swiggy contained about 10300 rows of information and Zomato contained 54000 rows of information.
Columns in Both the files were not equal. Also the files contained missing values, Long text values,
Location etcera.
Common Columns included Name of the restaurant, Rating, Cost for people Dining, location area and
url.
The text data had to be cleanned for emoji's, special characters
etc. I have used regular express and another module called as Clean-Text in-order to clean the text
data column.
The numerical columns contained missing values. Duplicated
Values as well. Those have to be addressed as well.
Not all numerical columns could be filled with zeros. Depending on the nature of the column and the
values which are representing the column,
Numerical columns have to be filled for Missing Values. Although Duplicates can be removed easily.
Once the datasets were combined and cleanned, The Data in the
pandas frame was saved to .csv file for all the later use.
Running the preprocessing everytime before the modeling in the jupyter file is not advisible. It
takes a lot of time to run the file. So saving the cleanned data in another file is a good practice.
**** Please click on Data Preprocessing tab to view the data Preprocessing code or click here
⇛ Exploratory data Analysis
I have used Statistical ways to build the graph and draw
meaningfull insights from the data.
The explanantion for each graph and the dashboard are clearly described in the Analysis page and
Dashboard Page. I have also used Tableau to build the dashboard.
The Overall insights and conclusion drawn from the data are
explained in the Analysis page.
I have also done sentiment analysis of the reviews and rating
of restaurants given by customers while ordering food. This was necessary to know how the reviews
and rating affect the increase of sales of the particular Restaurants. The Restaurants have received
both Positive and negative ratings from various customers. Despite the ratings, Restaurants have
never failed to give their great service and customer satisfaction.
**** Please click on Data analysis tab to view the Exploratory Data Analysis and Visualization code
or
click here
For Dashboard click here.
Dashboard of the Analyzed Data
**** Please check out the sentiment anlysis tag and dashboard for the explanation and code.
⇛ Data Transformation
For the machine learning model, the data have to be scaled and
encoded so that the model can understand the numbers.
The dataset I created did not come in separate train and test
and validation set.
For the machine learning the spliting of data is highly required to avoid bais and variance of the
trained model.
**** Please click on ML Model tab to view the Data Transformation explanantion and code or click here
⇛ Building Machine learning models
There are many Machine Learning model architures.
When I saw the dataset, I wanted to build a machine learning model based off user's reviews,
cuisines, restaurant type and location
Cuisinies, restaurant type and location were categorical variables. The restaurants can be
grouped based on location using clustering architures.
The best suited architecture is K-means clustering algorithm.
Also I wanted to build a model based on users rating as well. Since Rating was a numerical
column, I could easily apply ensemble machine learning model such as XG-Boost. I also tried SVM
algorithm.
One of the famous filtering method is collaborative filtering using TFIDF. I used this
technique on users reviews and Cuisines they serve to filter out the
restaurants depending on sentiments scores obtained using TFIDF vectorization and NLP techniques.
After this I tested the model with the test data as well. In onrder to validate the trained model i
used K-fold cross validation technique.
The final results were ploted and for collaborative filtering I tested out the function using
the name of the dish.
**** Please click on ML Model tab to view Building Machine learning explanantion and code or click here
Working Model
I prepared a small page which suggests the restaurants based on user input. Due to some unaviodable reasons I couldnt provide the deployed link over here. However, the django project is available on github. The link is here.