Building Machine Learning models on Restaurants Datastet
Introduction to model selection
There are supervised and unsupervied machine learning algorithms
for making a recommendation system. I
am going to use unspervied algorithms to make the model. I will be using k-means algorithm for
clustering the restaruant based on different areas in bengaluru. I will also be using TFID method to
make the recommedations based on the type of the restaurant.
There are many Machine Learning model architures.
When I saw the dataset, I wanted to build a machine learning model based off user's reviews,
cuisines, restaurant type and location
Cuisinies, restaurant type and location were categorical variables. The restaurants can be
grouped based on location using clustering architures.
The best suited architecture is K-means clustering algorithm.
Also I wanted to build a model based on users rating as well. Since Rating was a numerical
column, I could easily apply ensemble machine learning model such as XG-Boost. I also tried SVM
algorithm.
One of the famous filtering method is collaborative filtering using TFIDF. I used this
technique on users reviews and Cuisines they serve to filter out the
restaurants depending on sentiments scores obtained using TFIDF vectorization and NLP techniques.
After this I tested the model with the test data as well. In onrder to validate the trained model i
used K-fold cross validation technique.
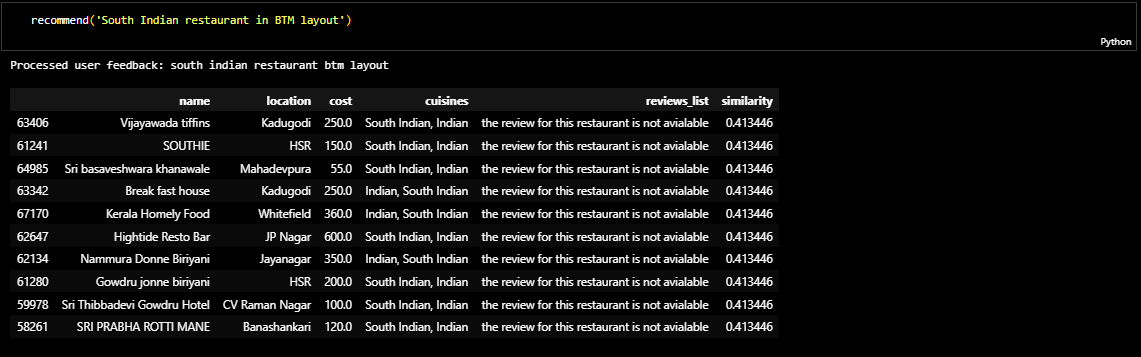
The final results were ploted and for collaborative filtering I tested out the function using
the name of the dish.
Data Transformation
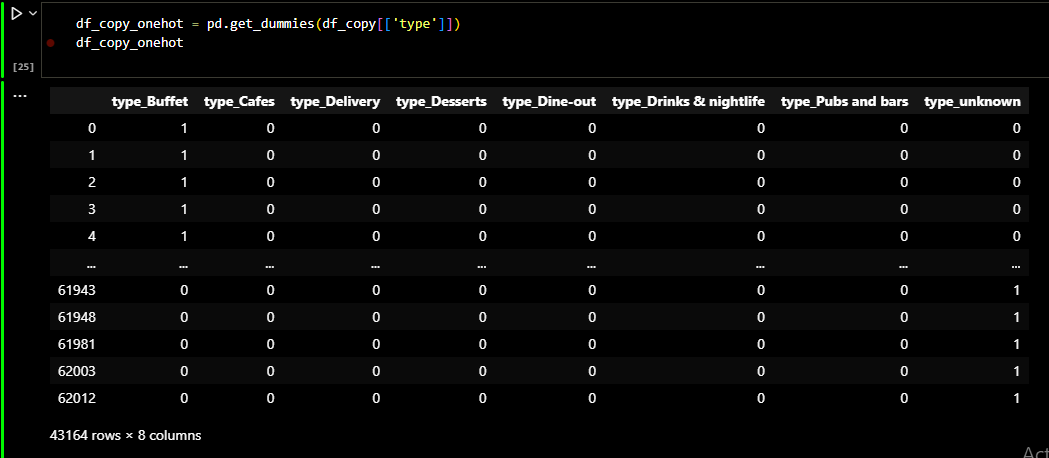
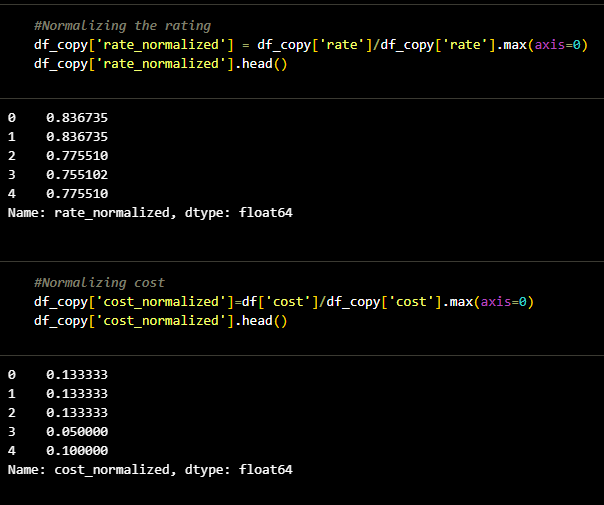
Before applying any algorithm, the first step is to scale and transform the raw data into ml model ready input. To acheive this I used one hot encoding. One hot encoding is a method to convert the categorical features into a machine readble values which can be later used for modeling
To acheive this I used get_dummies from pandas module. I made sure that the cuisines are grouped
according to type of the restaurant. Later I again grouped based on different areas of location in
Bengaluru.
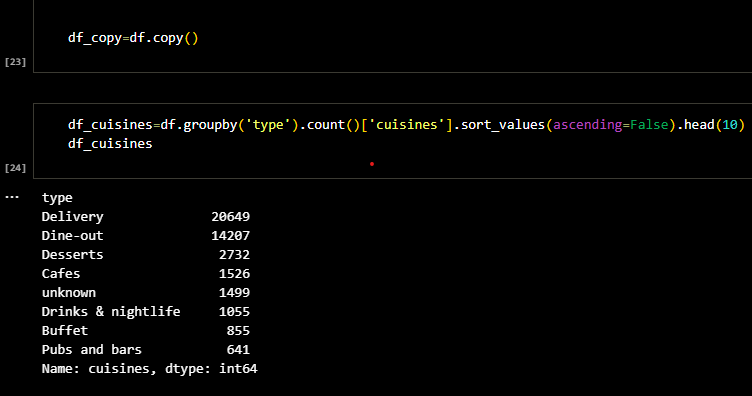
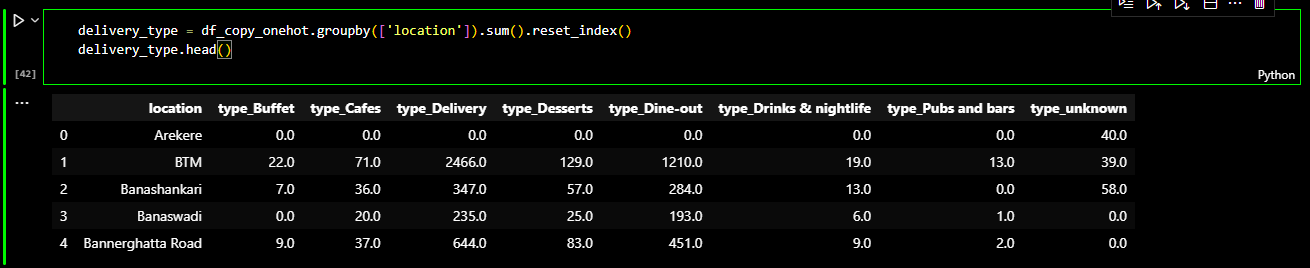
I checked for the number of occurance of each type of restaurant and tried to sort the
restaurant based on frequency of occurance. For easier representation, I turned this output into a
pandas dataframe.

A brief of K-means clustering
k-means clustering is a method of vector quantization, originally from signal processing, that aims
to
partition n observations into k clusters in which each observation belongs to the cluster with the
nearest mean (cluster centers or cluster centroid), serving as a prototype of the cluster. This
results
in a partitioning of the data space into Voronoi cells. k-means clustering minimizes within-cluster
variances (squared Euclidean distances), but not regular Euclidean distances, which would be the
more
difficult Weber problem: the mean optimizes squared errors, whereas only the geometric median
minimizes
Euclidean distances. For instance, better Euclidean solutions can be found using k-medians and
k-medoids.
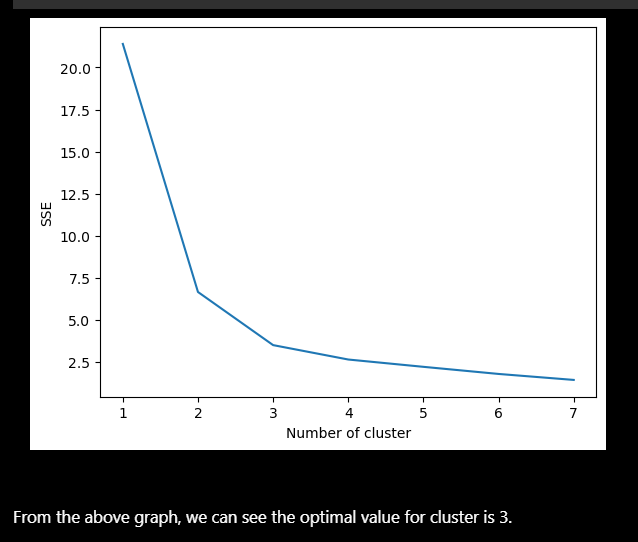
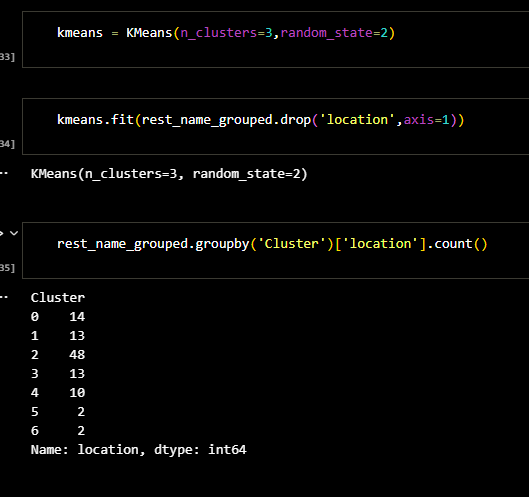
The first step in implementing the algorithm is to find the number of clusters. Second,
instansiate the algorithm class and
fit our data into the model. The following figures shows the exact methods I used. I found that
number of clusters were 3 for this problem.

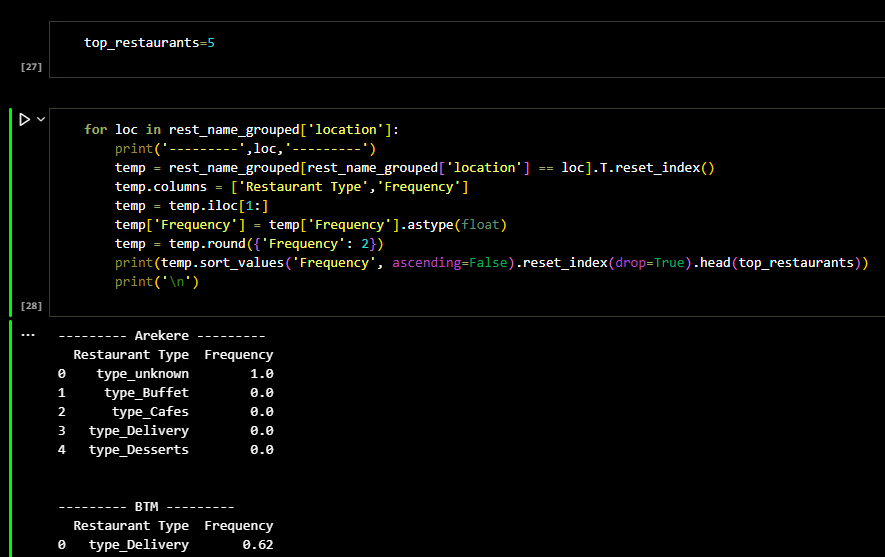
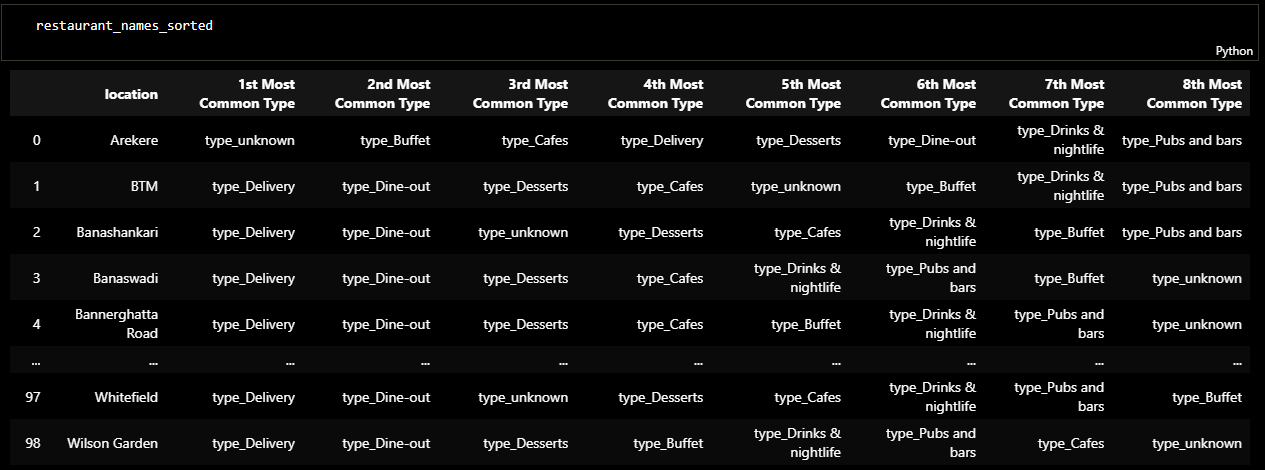
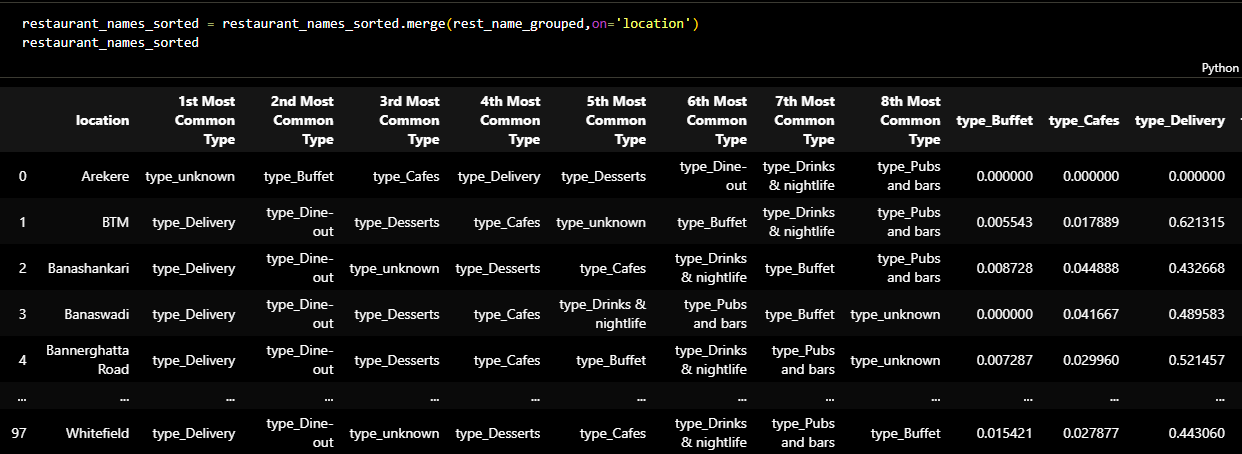
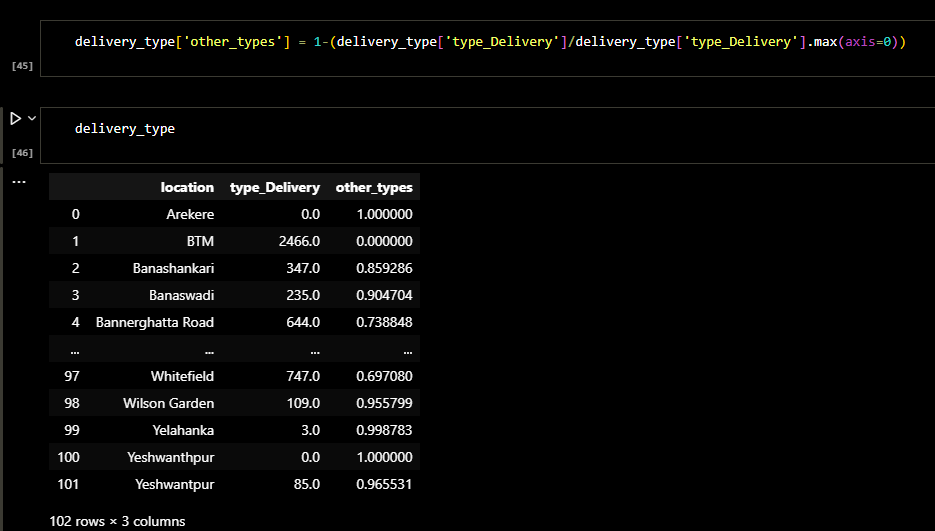
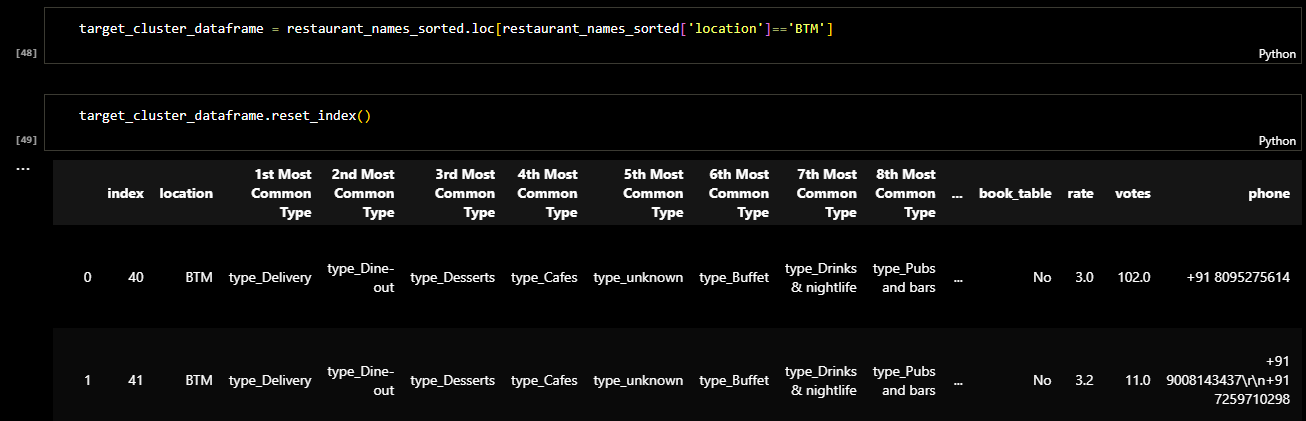
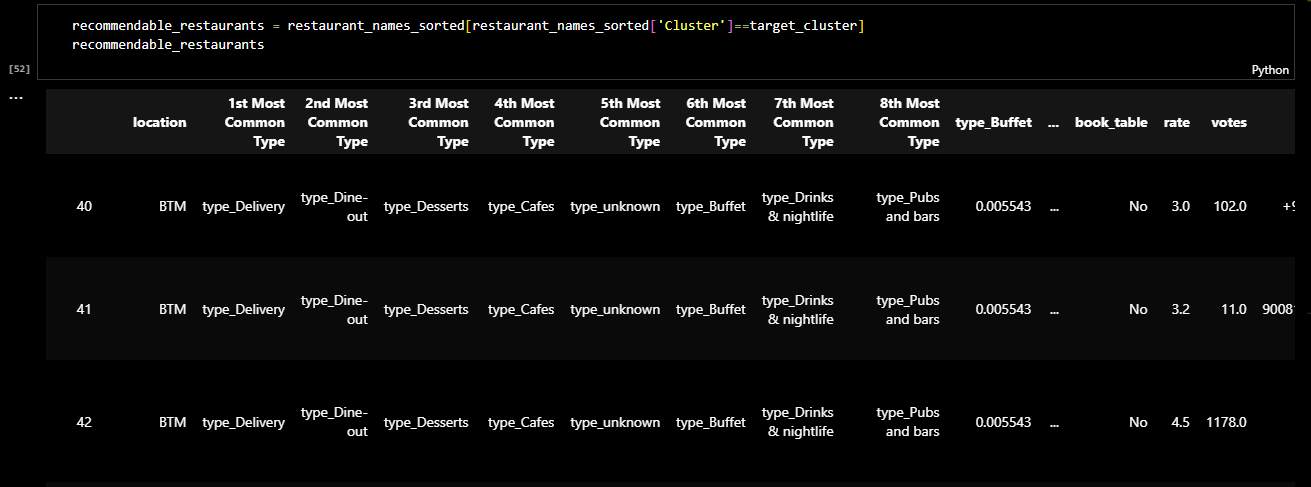
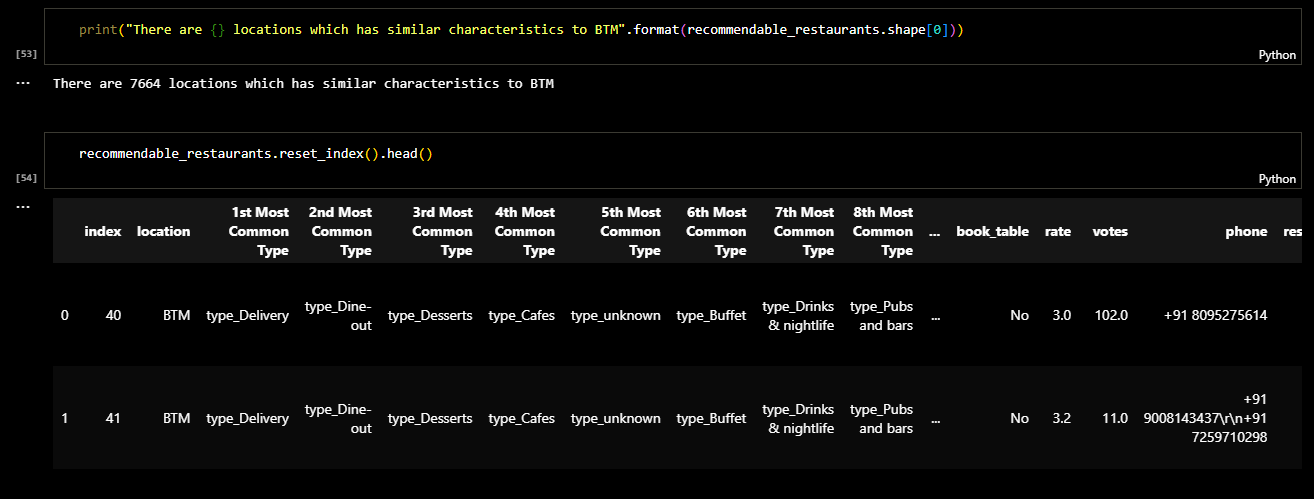
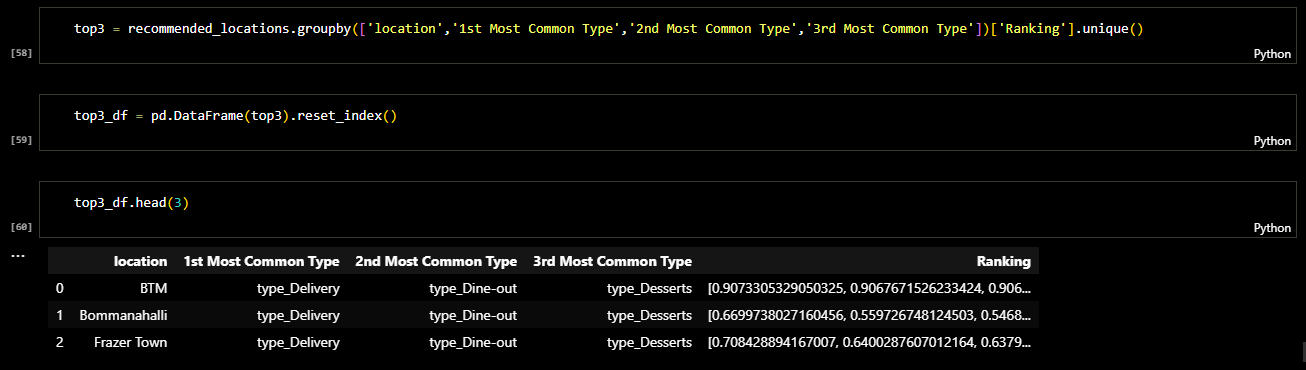
Later I checked the columns of the dataframe and sorted it. The result was a dataframe in which the
restaurants were clustred based on type of the restaurant and location. The following figure shows
the ranking of restaurant types in each area of location.



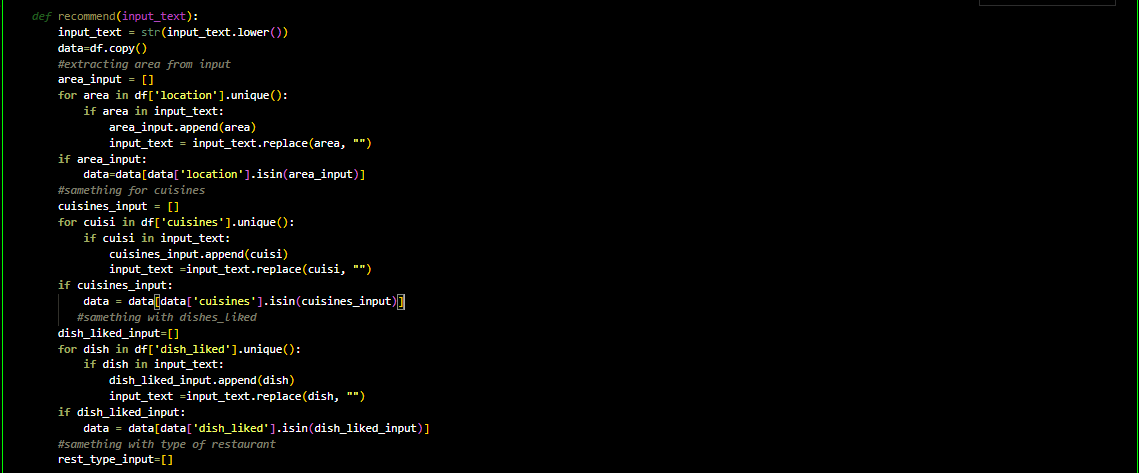
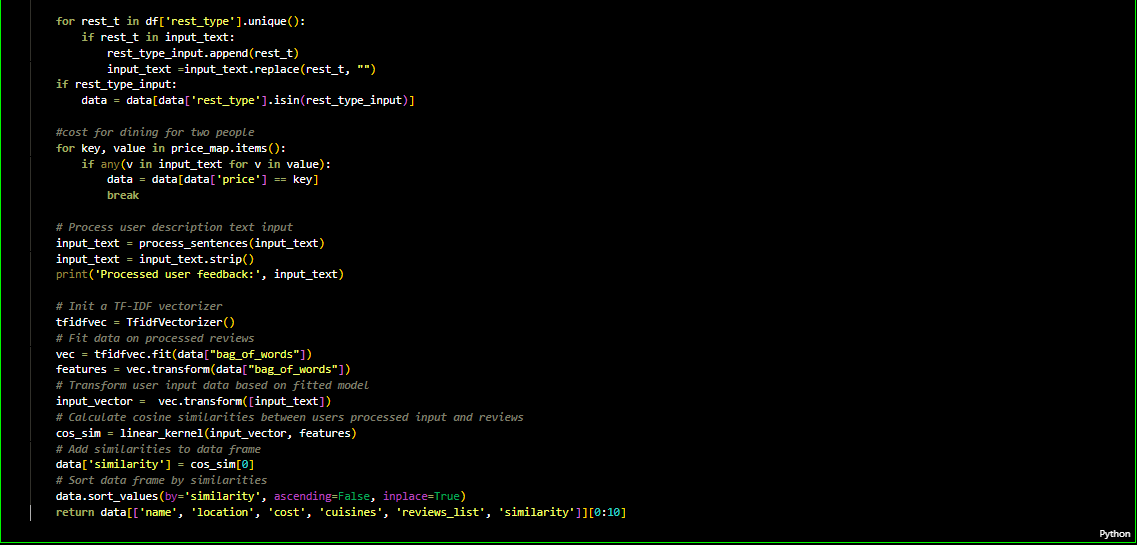
Content Based Recommendation
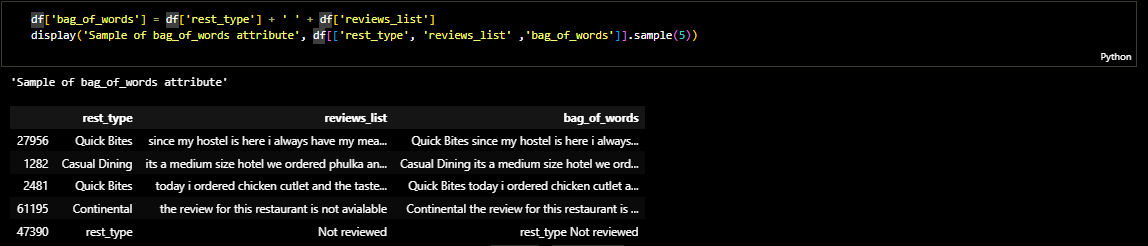
TF-IDF Matrix (Term Frequency — Inverse Document Frequency Matrix) TF-IDF method is used to quantify words and compute weights for them.In other words, representing each word (or couples of words etc.) with a number in order to use mathematics in our recommender system. Put simply, the higher the TF*IDF score (weight), the rarer and more important the term, and vice versa Cosine similarity is a metric used to determine how similar the documents are irrespective of their size. Here, the tfidf_matrix is the matrix containing each word and its TF-IDF score with regard to each document, or item in this case. Also, stop words are simply words that add no significant value to our system, like ‘an’, ‘is’, ‘the’, and hence are ignored by the system.[3] Now, I have a representation of every item in terms of its description. Next, I need to calculate the relevance or similarity of one document to another.






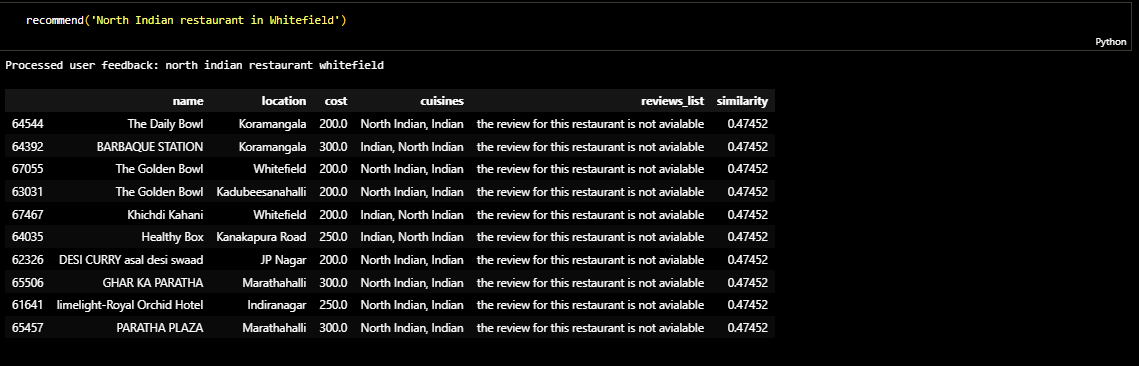

Testing of models
I prepared a website which shows the top 10 recommended restaurants for a search query. Due to unaviodable surcumstances I couldnt host it. You can still see the recommender function and other code below. Please click on the link below.
Restaurant suggesstor