Data Preprocessing
Necessity of Preprocessing
To beign with I collected Zomato Restaurants Data from
kaggle.com and Extracted other data from Swiggy using a scraping bot. Zomato and Swiggy are popular
apps where most of the food orders are placed on daily Basis by people in Bengaluru.
The Project involes restaurants in Bengaluru.The Dataset is
obtained by scraping the two popular online delivery systems. Swiggy and Zomato. The dataset is
separately obtained and later combined to make it as one file. The size of the individual files are
0.5GB and 100MB respectively from Zomato
and Swiggy.
Before combining I have cleanned individual columns for any
null values, unrequired values in text data etcetra.
All the code which I followed to create the new dataset are clearely shown in the following
sections.
Process implemented
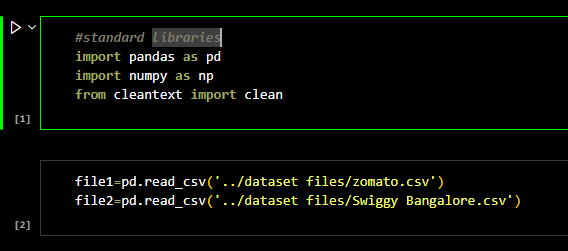
To clean the data, I required pandas and clean-text module. Two separate files in the csv format was
read using pandas Dataframe
 Both the files have restaurants name, area in which they are located, rating, cost of dining for two
people columns.
Although they are categorised under different column names. I renamed the 2nd file columns to merge
with the first file.
Once combined, I started the cleaning process. The first file came with 17 columns and 51717 rows of
information.
Whereas the second file came with 7 columns and 10298 rows of information.
Both the files have restaurants name, area in which they are located, rating, cost of dining for two
people columns.
Although they are categorised under different column names. I renamed the 2nd file columns to merge
with the first file.
Once combined, I started the cleaning process. The first file came with 17 columns and 51717 rows of
information.
Whereas the second file came with 7 columns and 10298 rows of information.
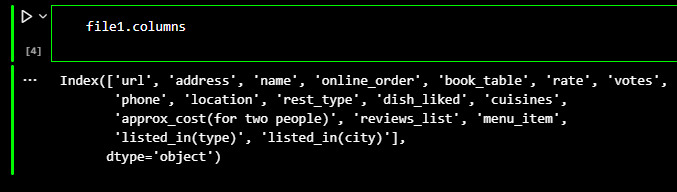
File 1 had the following columns.
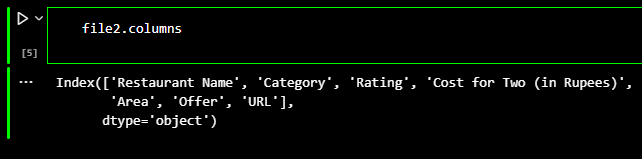
File 2 had the following columns.
 I merged the files.
I merged the files.
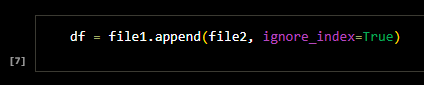
Before cleaning I made sure the index column was fixed and the columns were renamed
properly.
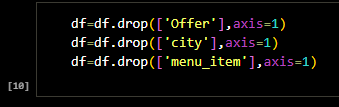
DataFrame came with columns which did not contribute to overall analysis. They were time limited
Offers given out by the restaurants. I retained other unrequired columns such as phone numbers, url
and address columns as they will be come in handy in the final product. The offer is an inclusive
thing which the restaurants decide depending on the season. I will clean rate column, votes column,
cost column as they are numerical columns.
Another important thing is to clean categorical columns such as address, online order, book
table, rest type, dishes liked, cuisines, review list, menu item. City column was repeated. Menu
Item was an individual length array.
At some time after this analysis. I would use the menu column to build a food recommending system.

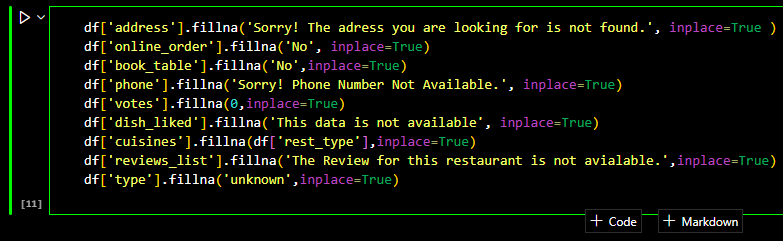
The categorical columns like dishes liked, cuisines, type of restaurants,
book_table,
online_order, came with lot of null values. I replaced respective columns with appropriate values in
place of null values. I also filled address and phone columns with a string message. For Statistical
analysis I did drop these unknown values and did the analysis on the rest of the available data.
Drawing conclusions on the unknown data is difficult. Its going be purly perspective analysis if I
try to include those values. The below picture depicts the procedure I followed to fill Null values.
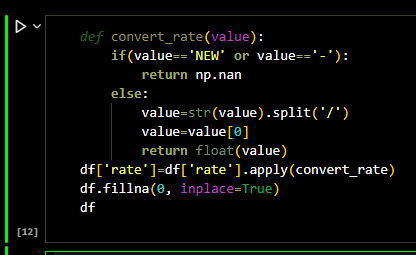
Coming to the Rating of the restaurants, rating had unique values like 'NEW', '_',.
The rating
column which was in original zomato dataset had rating in '/5' format, meaning for example 4.5 out
of 5, whereas the rating column in Swiggy Dataset was just a number. (for example 4.5)
To avoid this confusion, I removed '/5', and other inappropriate values. I used the following
function to do the job. I also made sure that the rating was a float value. Rating came as a string
type column.
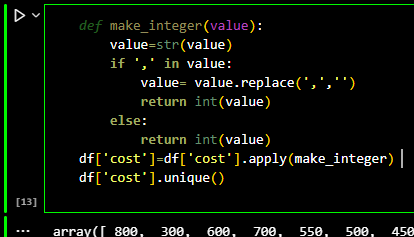
The cost for two people contained ',' for indicating thousands in denomination. This
column
turned out to be a string column.
I wrote a function which removes the ',' and converts the column value into a nteger type of value.
I chose integer type specifically because the restarants menu cost were in rounded values rather
than fractions. Besides no one pays in paises.
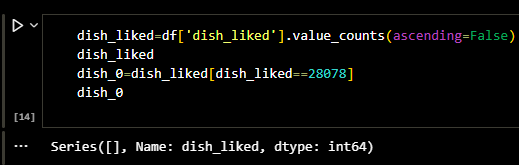
The Dishes liked by people contained a lot of null values. So I had to remove those. To do this I
made the following function.
I simply checked if the column had null, took that into a separate array and if any value was
similar to the values in this array
I replaced it with 'Not rated item.'
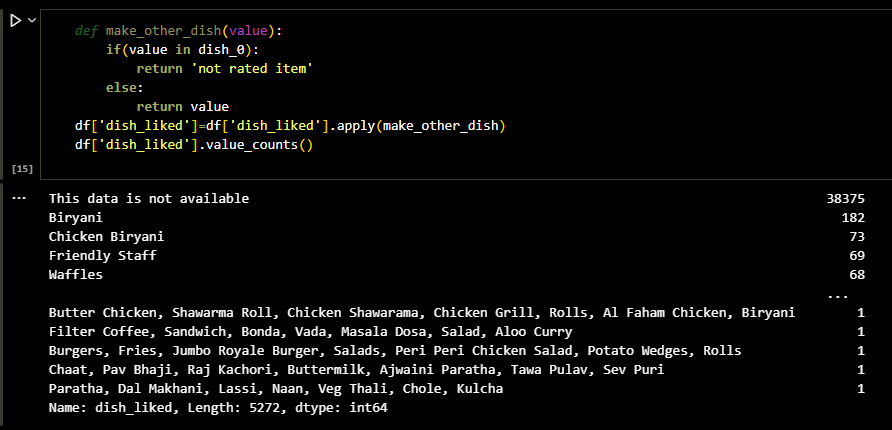
Reviews column was another major data which actully describes the users experience as well as
Restaurant's performance.
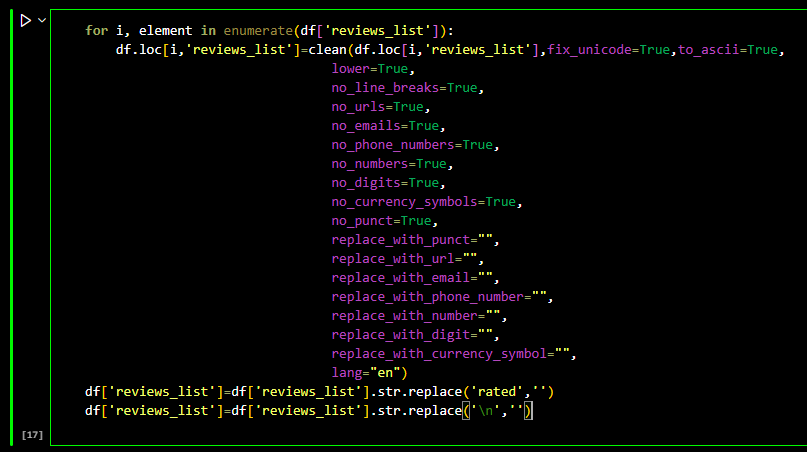
This column was an object column with text data. To clean all the text data, I implemented the
following loop.
Function Looks complicated, but is very simple. Its just removing unwanted characters including
symbols, phone numbers, emails, urls, digits, currency symbols,
puntuations, new line entries, also every review came with '\rated', which was unrequired. I did try
function to implement this logic, but it was exahustive and consumed a lot of RAM and time.
Later I saved the file as most of the required columns were cleanned. I did not want to alter
the address, url, phone_number column
Please check the Analyis and ML model page for further preocessing of the data.